
In the following weeks, we will introduce speakers of the SEMANTiCS conference and explore more about their fields of expertise. We start the series with Alan Morrison, who is a senior research fellow at PWC. He helps business leaders explore the future of technology and focus on how to use technologies together most effectively in their transformation efforts. Some of his recent PwC research has focused on artificial intelligence, virtual assistants, blockchain and smart contract automation, drones, the internet of things and NoSQL databases.
Alan’s keynote at SEMANTiCS will address how technology innovation and especially the adoption of AI impacts new business models.
Organizations embrace Artificial Intelligence solutions to automate their processes and want to benefit from Big Data. How many companies are really mature enough to work with this innovative technologies and develop them further? Which “basics” need to be covered before it makes sense to start an AI and Data Analytics initiative at a company?
Alan Morrison: Most companies can work with data at a small scale on a one-off project in a sophisticated way and achieve limited success. The real question is, how can they work with data at scale on a continual, day-to-day basis? Without continual flows of the right data to the right place, how can they transform their operations and achieve true competitive advantage?
Organizations need to start working with data flows, not just in batch mode. Rigid organizations are trapped in single-mode thinking, while their most able competitors are creative, non-linear thinkers who leverage a diversity of views and approaches to achieve business goals.
Data is the lifeblood of any sizable organization today, and competitive advantage hinges on the ability of companies to harness machines to develop and act on insights to effect considerable performance improvements and other beneficial outcomes. To uncover those insights, companies need a continual flow of the right data to the right parts of the organization in the right format.
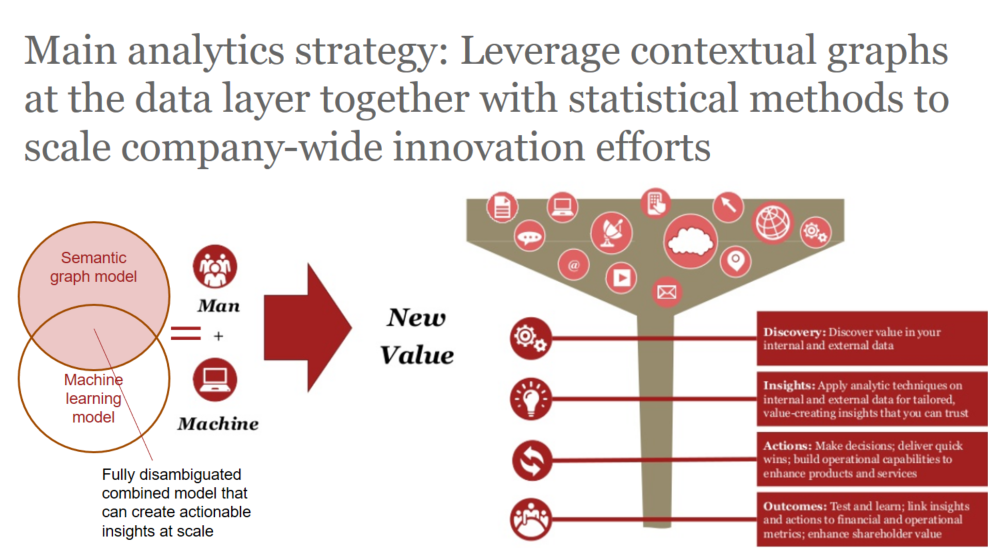
Companies need breadth in how they treat data as well as depth. Surely it’s great to become fluent in machine learning, but as with other emerging technologies, it’s not a hammer, and everything else doesn’t just look like a nail. It’s a programming paradigm enabling a continual learning loop that has to be in the mix, but it’s not the only approach you need. You actually need at least three programming paradigms in today’s business world.
Equally important and underused is the declarative programming paradigm because that serves as the continually evolving, contextual model of your organization and how it relates to the rest of the world. That semantic graph model learns too, and is symbiotic with machine learning and advanced analytics and should be blended with those statistical methods.
© PwC, 2018. All rights reserved. Used with permission.
The imperative programming paradigm is entirely overused and needs only to be used in conjunction with the other two methods, to tie those two symbiotic analytical paradigms to operations.
Companies who’ve got advanced analytics activities can make that transition when they view machine learning as the next step beyond advanced analytics. But without data as a true priority, they won’t be able to scale their machine learning efforts.
Discuss with Alan the potential of machine learning and semantic technologies at SEMANTiCS 2018. Register NOW and save up to € 150 Early Bird Discount until August 13!
With the explosion of data and advanced data processing capabilities, there is a growing demand for top notch experts as data scientists. How is the job market changing and which new job profiles will arise?
Alan Morrison: Data scientists are just the tip of the iceberg. Most companies aren’t aware of it yet, but they need knowledge engineers and so many other kinds of people to help them. Data scientists can have a narrow view of requirements—they work from project to project and by necessity are focused on solving problems that must be narrowly scoped.
Companies who aren’t technologically literate may be in the habit of asking random technologists who are down in the trenches questions about issues that can only be seen from a high altitude. That’s a habit they need to break. Companies need to become more data literate in general and develop independent strategic viewpoints on technology-related issues. PwC, for example, embarked on its own Digital Fitness initiative beginning in 2016, and offers the methods it uses to increase digital literacy internally now as an external service.
I track emerging technologies for a living, not just semantics, and have the privilege as a strategist to step back to do a kind of meta-analysis of how these technologies are becoming a part of the mix of approaches that have a business impact. I’m often wondering, how does the system benefit from the inclusion of particular tools? NoSQL databases, for example, offer companies more flexibility. But at a certain point, you need to avoid tool sprawl, so you have to be selective when it comes to how many database products you support.
If you take that same systems-level view and look at the job market, you will see more advanced organizations hiring for a range of different roles, including new roles. By doing so, they avoid groupthink and open themselves to the many different kinds of intelligence humans can bring to the mix.
You are a keynote speaker at SEMANTiCS 2018. You will speak about the incremental evolution of technology. Could you please describe what you consider as semantic technologies. Why do companies have to pay attention to this technology field?
Alan Morrison: Many people stumble over the term “semantics”. I tend to rely on metaphors and visualizations to help with understanding. When I’m able to teach myself a concept in a visual way, then I can share it with others. The visualization makes the understanding more easily transferable.
Graphs and how they can represent connections between people, places and things can articulate and scale all our knowledge of how the world works, in a machine readable form. Just think about how powerful those graphs can be. Those articulated connections, the bridge between human and machine knowledge, can be called semantic graphs.
To get to scale and business model agility, companies need to create a semantic graph foundation for AI. I’m a big fan of semantic graphs as the parent data structure that can manage all the children, because they allow full contextualization of disparate data types and machine readable articulation of the rich relationships that need to be mined in any organization.
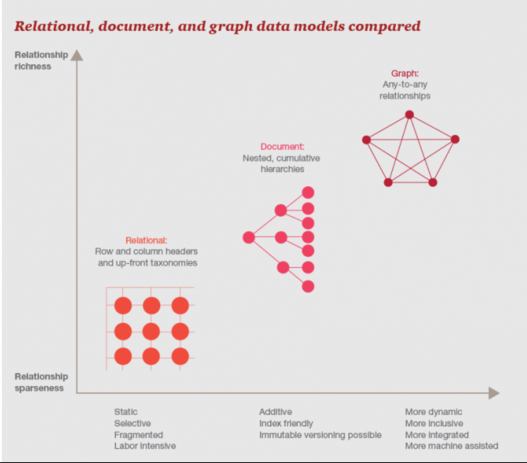
Relationship, not relational, data is what allows us to disambiguate and describe each context. Just ask a social media company—what’s more powerful than a graph to describe and better articulate customer relationships and all the segments and subsegments of the markets serving those customers? Just ask any fraud investigator—what’s a more powerful way than graphs to find bad actors?
Graphs as the parents, the most articulated data models, can easily incorporate less articulated models such as tables and documents—the children. That’s how large-scale integration happens. Business users need to think in terms of graphs much more often, and not just in terms of tables. Companies are hobbling themselves if they can’t get beyond tabular data models. Graphs hold the power of large-scale integration.
© PwC, 2018. All rights reserved. Used with permission.
What’s confusing to many is that semantic graphs are usually managed by humans in tabular or document or serialized form—RDF, XML and JSON-LD being prime examples. Machines can think in graphs, but humans often need to revert to tables or documents when the graphs scale out.
There’s no substitute for becoming more data model literate. The media is obsessed with data science, but there is no science without modeling. We have to represent and simplify in the process to be able to comprehend, and we need both semantic and statistical models. Visual models can help.
Machine learning systems need to leverage the power of semantic graphs. We’ve seen this over and over again. Machines can think in N dimensions and mine the various contexts described in multi-dimensional graphs. They need this level of articulation to generate outputs that are useful in each context. How can companies serve each part of the organization if the data isn’t contextualized?
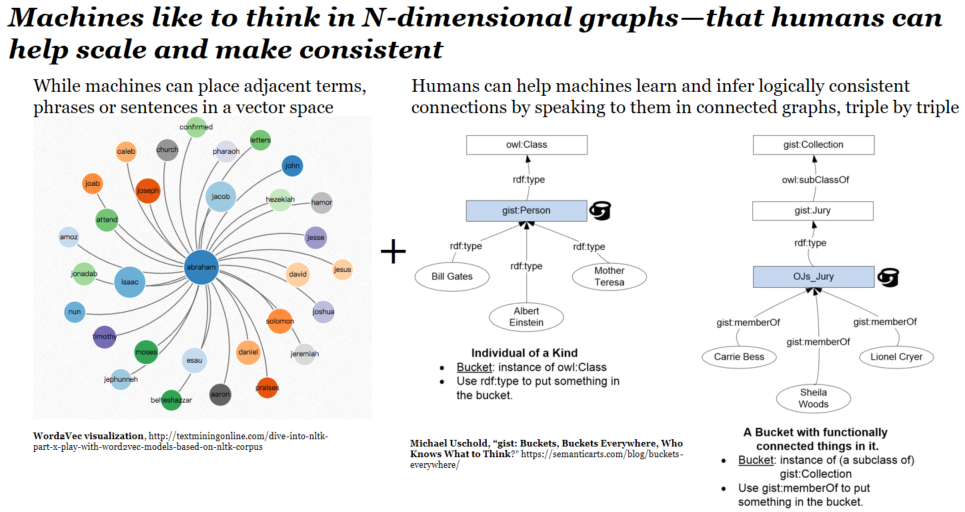
To work with data at scale, organizations need data integration and interoperability that provides benefits across departments. That’s most feasible with the help of semantic graphs.
About Alan Morrison
Alan Morrison is a senior research fellow at PWC. He helps business leaders explore the future of technology and focus on how to use technologies together most effectively in their transformation efforts. Some of his recent PwC research has focused on artificial intelligence, virtual assistants, blockchain and smart contract automation, drones, the internet of things and NoSQL databases.
Alan’s keynote at SEMANTiCS will address how technology innovation and especially the adoption of AI impacts new business models.
Discuss with Alan the potential of machine learning and semantic technologies at SEMANTiCS 2018. Register now!
